
基幹系システムの汎用データベースとして利用されているRDBMSですが、近年では情報系システムでも広く利用されています。今回は情報系システムの特徴を踏まえた上で、汎用データベースの課題について考えてみたいと思います。
情報系システムにおける処理の特徴
情報系システムのデータ基盤として知られるDWH。DWHという言葉は知っていても、DWH特有のデータモデルやSQLは意外と知られていないように見受けられますが、皆さんはいかがでしょうか。DWHならではのテーブル設計とSQLとは一体どのようなものなのか、まずは確認していきたいと思います。
情報系システムのテーブル設計
DWHの代表的なデータモデルであるスタースキーマを例に説明します。以下の図のように、スタースキーマはER図で表すと、中央のテーブルから放射状に各テーブルが配置されるため、その星状の形からそのように呼ばれています。分析対象となるファクト表を中央に配置し、分析軸となるディメンジョン表をその周りに配置することで、データを分析するユーザから見てもわかりやすいモデルだと言えます。
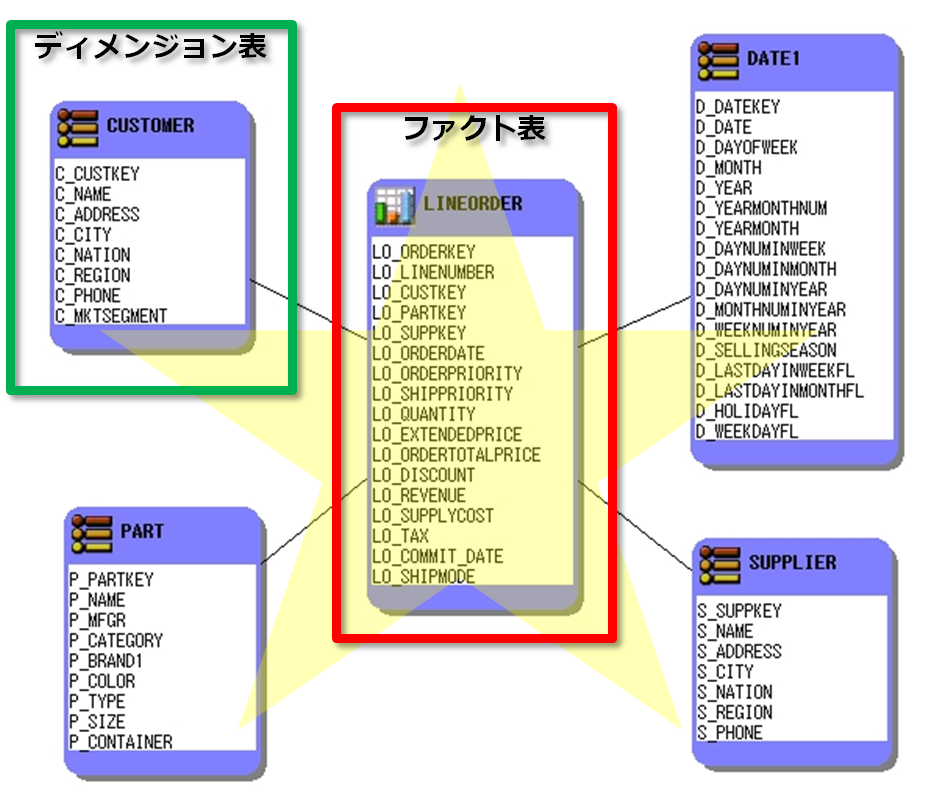
ここに例示したスタースキーマは、DWH向けのベンチマークツール(Star Schema Benchmark)から引用したものです。
Star Schema Benchmarkでは、LINEORDER表がファクト表であり、商品の購入履歴が時系列に蓄積されます。ファクト表は、分析対象となる実績値が格納される明細データであり、データ件数は億単位になります。
そして、残りの表(CUSTOMER表、SUPPLIER表、PART表、DATE1表)がディメンジョン表であり、顧客やサプライヤなどの識別キーや名称などが格納されます。ディメンジョン表は、ビジネス上の分析の軸になるマスターデータであり、データ件数は少ないのが特徴です。
また、スタースキーマにすることで、ファクト表に購入者の名前や住所といった冗長な文字列を保持する必要がなくなり、データ量の増加を抑えるメリットもあります。
情報系システムのSQL
次に、情報系システムで用いられるSQLの特徴について見ます。ここでも、Star Schema BenchmarkのSQLを引用します。以下の図のSQLには次のような特徴が確認できます。
①選択リストは分析軸と集約値
②ファクト表と複数のディメンジョン表を結合
③ディメンジョン表の分析軸が多様
④分析軸に対するグループ処理
②ファクト表と複数のディメンジョン表を結合
③ディメンジョン表の分析軸が多様
④分析軸に対するグループ処理

また、SQL全体を俯瞰してみると、次のような特徴についても確認できます。
・返される結果は数件だが、広範囲のデータがアクセス対象
・ファクト表の列数は多いが、SQLで指定されるのはごく一部
・ファクト表の列数は多いが、SQLで指定されるのはごく一部
それでは、このような特徴を持つ情報系システムの処理において、汎用データベースを利用した場合の課題とは一体どのようなものなのかについて見ていきたいと思います。
汎用データベースが抱える表走査の課題
汎用データベースは行単位で処理されるため、データの格納形式も行単位のアクセスに最適化された構造になっています。具体的には、以下の図のように、1つが8KB~32KBのデータブロックに対して、行単位に隣接する形でデータが格納されます。そのため、列数が多いとブロックに格納できる行数が少なくなり、結果としてブロック数が増加することになります。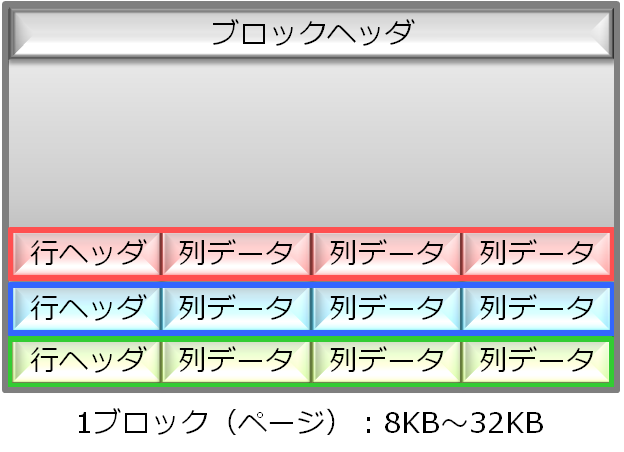
前掲のStar Schema BenchmarkのER図とSQLを見比べるとわかりますが、情報系システムの処理の場合、各表には多くの列が存在する一方で、アクセスされる列が少ない傾向にあります。
しかし、汎用データベースは行単位アクセスのため、このような処理で利用した場合には、処理対象でない列にもアクセスするといったI/O効率の課題があります。
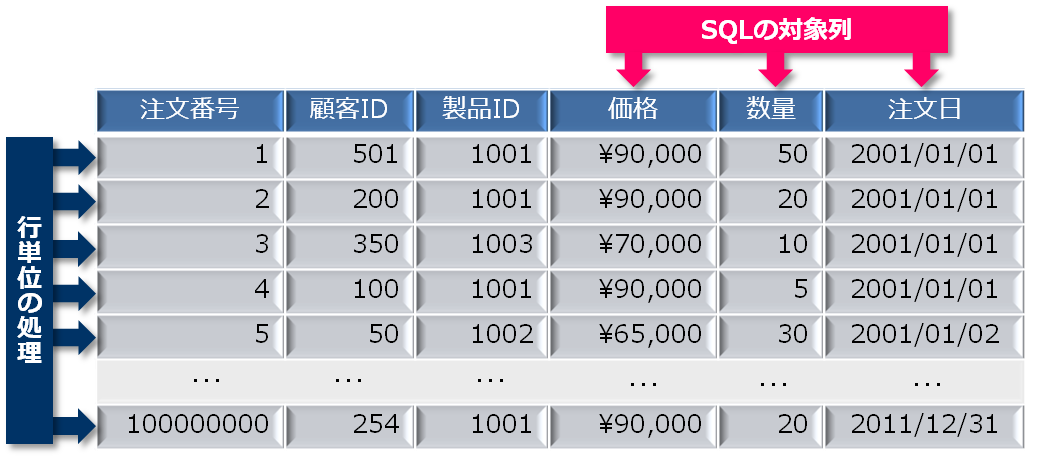
例えば、以下の図の表に対して、「注文日:2011年」を条件に「売上高(sum(価格×数量))」を集計する場合、処理に必要のない列(注文番号、顧客ID、製品ID)への無駄なアクセスでI/Oが増加し、パフォーマンス低下の原因となります。
汎用データベースが抱えるチューニングの課題
汎用データベースを情報系システムで利用すると、決められた時間内に処理が終わらないといった問題が頻出するようになります。そのため、基幹系システムでの経験に基づいて、索引によるI/Oの削減を試みる方も多いと思います。しかし、データ分析を目的とする情報系システムの場合、必ずしも索引が有効に働くとは限らないため、調整に苦慮することもしばしばです。ここでは、索引をはじめとした汎用データベースのチューニング課題について見ていきたいと思います。
①索引設計が難しい
◆ディメンジョンの分析軸が多様である何を条件にするか決まっている定型検索には有効な索引でも、分析軸が多数あることで検索条件を予測できない情報系システムでは、最適な索引を事前に設計することは困難です。
◆走査範囲が広い場合、索引が有効に機能しない
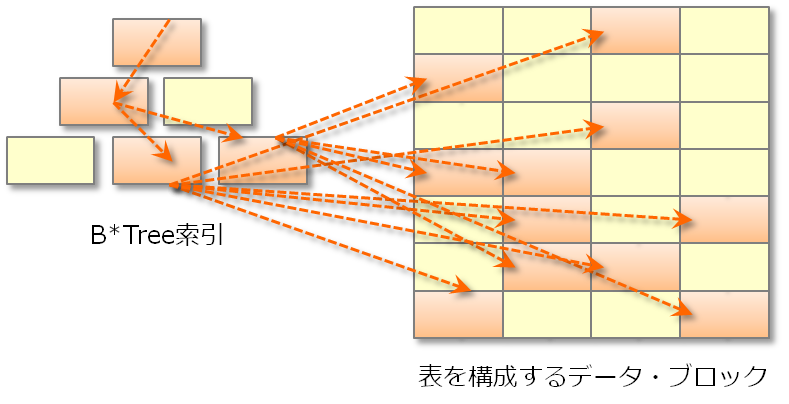
索引を用いたデータアクセスのイメージは、条件キーの値を基に索引からデータのアドレスを参照し、対象データが格納されたデータブロックにランダムアクセスします。
しかし、以下の図のように広範囲のデータがアクセス対象となる情報系システムの処理では、1件ずつ索引とデータにアクセスするアクセス方式は効率が良いとは言えません。
◆索引のメンテナンスが必要である
表のデータが追加/更新/削除されると、索引に対しても索引キーの値が追加/更新/削除され、索引の構成に偏りが生じるようになります。そのため、データへの均一なアクセスを担保するためには、索引を再構成する必要があります。
また、複数列で構成される複合索引を同じ列にいくつも定義した結果、途中から使われなくなる索引も出てきます。未使用の索引は無駄にメンテナンスされるだけでなく、無駄な領域を増加させたり、他の更新処理を遅延させるような悪影響も及ぼします。そのため、索引を利用する場合には、性能を維持する上で運用中のメンテナンスが必要となります。
②パーティションキーの設計が難しい
索引を用いずに行を絞り込む機能として、パーティショニング機能があります。例えば、売上表の売上年月に対してパーティションキーを設定した場合、SQLに指定した売上年月のデータに対してのみアクセスされるため、読み込みブロック数を大幅に減らすことができます。しかし、その一方で、パーティションキーの設計が難しく、データの分布に偏りがあると効果が出ないなどの課題があります。
また、パーティショニング機能はすべての汎用データベースで提供されているとは限らず、提供していてもオプション機能のために別途購入費用が発生する場合があります。
③データの圧縮率が高くない
汎用データベースにはデータの圧縮機能を提供しているものもあり、これによって読み込みブロック数を減らすことが可能となります。しかし、汎用データベースのデータは行単位で格納されるため、重複値による圧縮効果はあまり期待できません。また、圧縮データはすべての列が解凍されるため、無駄にCPUの使用率を上昇させてしまう課題があります。汎用データベースのチューニング種類には、以下の図のように索引やパーティショニング以外にも様々なものがあります。チューニング項目によっては、最適化の範囲や対象だけでなく、そのために必要となるコストやスキルなども異なります。そのため、どのようなチューニングを実施するのかは、企業が抱える事情によっても変わってきます。
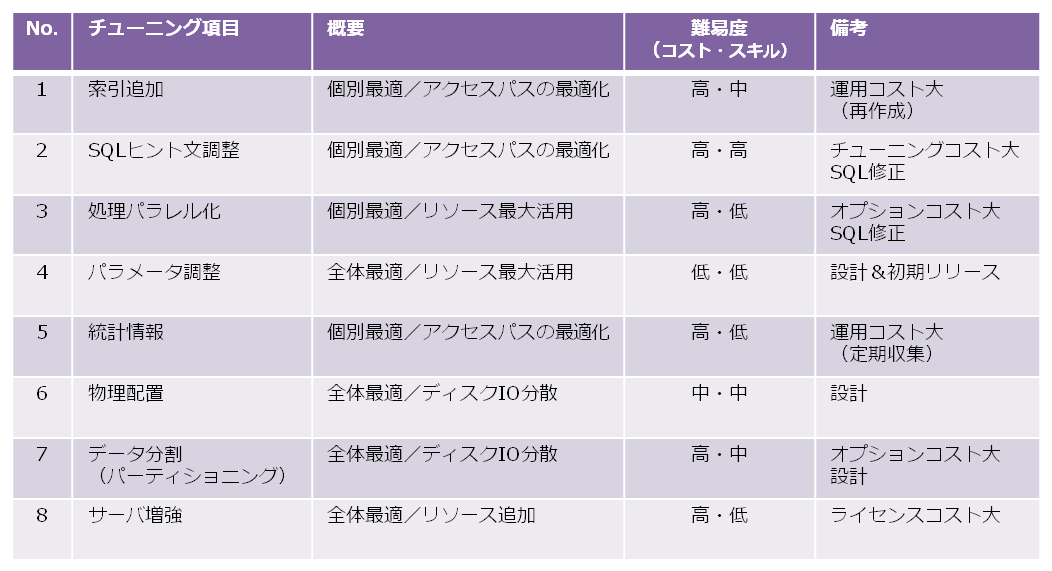
いずれにしても、性能問題は一朝一夕で解決できるものではなく、今後もコスト増の源になり続けます。
情報系システムに特化していない汎用データベースを使い続ける限り、性能を改善/維持するためのチューニングとメンテナンスは、今後も取り組まなければならない重要課題となります。
その課題を解決するために登場した製品が、DWHアプライアンスやDWHソフトウェアです。
参考情報
上記課題を解決するデータベースについては、こちらのコラムで取り上げます。・情報系システムに適した列指向型データベース
http://vertica-tech.ashisuto.co.jp/column-oriented-database-suitable/

