
目次
はじめに
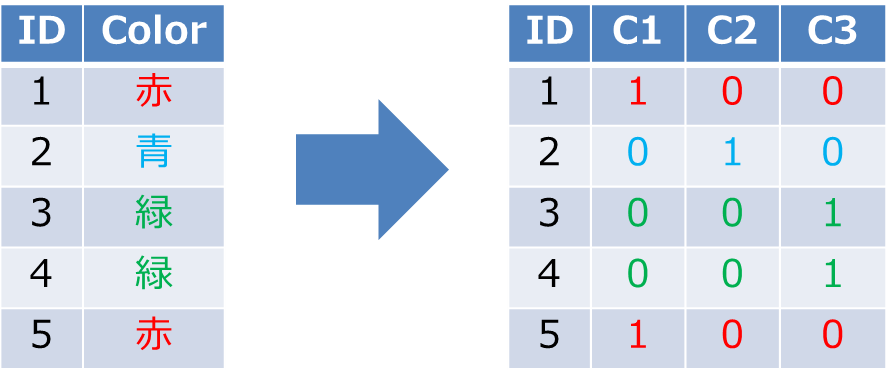
機械学習を行う際、多くの場合はカテゴリデータをそのまま利用することはできないため、事前にベクトル表現に変換する必要があります。例えば、カラー列に「赤」、「緑」、「青」の三種類のデータがある場合単純に赤→[1]、緑→[2]、青→[3]に置き換えると、機械学習の結果に悪影響が生じることがあります。上記データの場合1から3までのユークリッド距離は1から2までと比較して2倍になります。つまり
「赤(1)」と「青(3)」より「赤(1)」と「緑(2)」の方が距離が近い(似ている)ことになってしまいます。
この問題を回避するために各値をバイナリベクトルにマッピングします。
例えば上記カラー列の場合は以下のようにマッピングできます。
赤→[1,0,0]、緑→[0,1,0]、青→[0,0,1]
これをOne-hot表現と言います。
Vertica 9.0より、ONE_HOT_ENCODER_FIT/APPLY_ONE_HOT_ENCODER関数を使用することで、上記のようなOne-hot表現を簡単に行うことが可能になりました。
ONE_HOT_ENCODER
コマンド構文
|
1 2 3 4 5 |
dbadmin=> SELECT ONE_HOT_ENCODER_FIT ( 'model_name', 'input_relation','input_columns' -> [USING PARAMETERS [exclude_columns='col1, col2, ... coln',] -> [output_view='output_view',] -> [extra_levels='json_string'] -> ]); |
| パラメータ名 | 意味 |
|---|---|
| model_name | 任意のモデル名 |
| input_relation | 対象テーブル名 |
| input_columns | 対象列名 |
| exclude_columns | (オプション) 対象列を*(全列)と指定した場合に、対象列から除外する列 |
| output_view | (オプション) 対象テーブルにOne-hot表現に変更した列を付与した結果を保存するビュー |
| extra_levels | (オプション) 対象テーブルに存在しない各カテゴリの追加のレベルを指定します。 |
利用例
性別データが格納されているt1テーブルを例にします。|
1 2 3 4 5 6 7 8 9 |
dbadmin=> select * from t1; id | gender ----+--------------- 1 | Female 2 | Male 3 | Not specified 4 | Female 5 | Not specified (5 rows) |
gender列の値をOne-hot表現に変換します。
|
1 2 3 4 5 6 |
dbadmin=> SELECT ONE_HOT_ENCODER_FIT('t1_encoder', 't1', 'gender'); ONE_HOT_ENCODER_FIT --------------------- Success (1 row) |
変換内容のサマリー情報はGET_MODEL_SUMMARY関数で確認できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
dbadmin=> SELECT GET_MODEL_SUMMARY(USING PARAMETERS model_name='t1_encoder'); GET_MODEL_SUMMARY ---------------------------------------------------------------------------- =========== call_string =========== SELECT one_hot_encoder_fit('public.t1_encoder','t1','gender' USING PARAMETERS exclude_columns='', output_view='', extra_levels='{}'); ================== varchar_categories ================== category_name|category_level|category_level_index -------------+--------------+-------------------- gender | Female | 0 gender | Male | 1 gender |Not specified | 2 (1 row) |
この情報を利用して、実際にOne-hot表現に変換する際は、APPLY_ONE_HOT_ENCODER関数を利用します。
|
1 2 3 4 5 |
dbadmin=> SELECT APPLY_ONE_HOT_ENCODER( 'input_columns' -> USING PARAMETERS model_name -> [, drop_first='{false | true}',] -> [ignore_null='{false | true}',] -> [separator='method']); |
| パラメータ名 | 意味 |
|---|---|
| input_columns | 対象列名 |
| model_name | 対象モデル名(ONE_HOT_ENCODER_FIT関数で作成したモデルを指定) |
| drop_first | (オプション) Falseの場合、カテゴリ変数のすべてのレベルに対応する列が出力ビューに表示されます。 Trueの場合、カテゴリ変数の最初のレベルは参照レベルとして扱われます。(デフォルト:True) |
| ignore_null | (オプション) Falseの場合、対象列のNULL値はカテゴリレベルとして扱われます。 Trueの場合、NULL値は対応する1ホットバイナリ列をすべてNULLに設定します。(デフォルト:True) |
| separator | (オプション) 出力表の入力変数名と標識変数レベルの間の区切り文字を示します。 セパレータを使用したくない場合はNULLを指定します。(デフォルト:_(アンダースコア)) |
ONE_HOT_ENCODER_FIT関数を利用して作成したt1_encoderを使用して、実際にOn-hot表現に変換します。
|
1 2 3 4 5 6 7 8 9 10 |
dbadmin=> SELECT APPLY_ONE_HOT_ENCODER(* USING PARAMETERS model_name='t1_encoder') dbadmin-> FROM t1; id | gender | gender_1 | gender_2 ----+---------------+----------+---------- 1 | Female | 0 | 0 2 | Male | 1 | 0 3 | Not specified | 0 | 1 4 | Female | 0 | 0 5 | Not specified | 0 | 1 (5 rows) |
上記の場合、以下のようにマッピングされていることがわかります。
Female→[0,0]、Male→[1,0]、Not specified→[0,1]
このように、ONE_HOT_ENCODER_FIT/APPLY_ONE_HOT_ENCODER関数を使用することで、簡単にOne-hot表現に変換することができます。
応用例:タイタニック乗船者の生死予測のデータ準備でOne-hot表現変換を行う
機械学習のデータ準備としてONE_HOT_ENCODER_FIT/APPLY_ONE_HOT_ENCODER関数を利用する例をご紹介します。本例ではタイタニックデータセットを利用して、どの乗客がタイタニック号の沈没を生き延びたかをロジスティック回帰を使用して予測します。
 ※タイタニックデータセットの詳細についてはkaggleのサイトをご参照ください。
※タイタニックデータセットの詳細についてはkaggleのサイトをご参照ください。データ準備
学習データとして「titanic_training」テーブルを使用します。本テーブルにはpassenger_id(乗客ID)、survived(助かったか否か)、pclass(乗客の階級)、name(名前)、sex(性別)、age(年齢)、sibling_and_spouse_count(兄弟、配偶者の数)、parent_and_child_count(両親、子どもの数)、ticket(チケット番号)、fare(チケット料金)、embarkation_point(乗船場所)という情報があります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
dbadmin=> SELECT * FROM titanic_training limit 10; passenger_id | survived | pclass | name | sex | age | sibling_and_spouse_count | parent_and_child_count | ticket | fare | cabin | embarkation_point --------------+----------+--------+----------------------------------------------------+--------+-----+--------------------------+------------------------+-----------------+---------+-------+------------------- 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22 | 1 | 0 | A/5 21171 | 7.25 | | S 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Thayer | female | 38 | 1 | 0 | PC 17599 | 71.2833 | C85 | C 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26 | 0 | 0 | STON/O2. 310128 | 7.925 | | S 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35 | 1 | 0 | 113803 | 53.1 | C123 | S 5 | 0 | 3 | Allen, Mr. William Henry | male | 35 | 0 | 0 | 373450 | 8.05 | | S 6 | 0 | 3 | Moran, Mr. James | male | | 0 | 0 | 330877 | 8.4583 | | Q 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54 | 0 | 0 | 17463 | 51.8625 | E46 | S 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2 | 3 | 1 | 349909 | 21.075 | | S 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27 | 0 | 2 | 347742 | 11.1333 | | S 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14 | 1 | 0 | 237736 | 30.0708 | | C (10 rows) |
本例ではsurvived(助かったか否か)を予測する説明変数としてpclass、sex、age、sibling_and_spouse_count、parent_and_child_count、fare、embarkation_point列を利用しますが、sex、embarkation_point列は文字列であり、そのままでは機械学習には利用できません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
dbadmin=> SELECT pclass,sex,age,sibling_and_spouse_count,parent_and_child_count,fare,embarkation_point -> FROM titanic_training LIMIT 10; pclass | sex | age | sibling_and_spouse_count | parent_and_child_count | fare | embarkation_point --------+--------+-----+--------------------------+------------------------+---------+------------------- 3 | male | 22 | 1 | 0 | 7.25 | S 1 | female | 38 | 1 | 0 | 71.2833 | C 3 | female | 26 | 0 | 0 | 7.925 | S 1 | female | 35 | 1 | 0 | 53.1 | S 3 | male | 35 | 0 | 0 | 8.05 | S 3 | male | | 0 | 0 | 8.4583 | Q 1 | male | 54 | 0 | 0 | 51.8625 | S 3 | male | 2 | 3 | 1 | 21.075 | S 3 | female | 27 | 0 | 2 | 11.1333 | S 2 | female | 14 | 1 | 0 | 30.0708 | C (10 rows) |
そのため、学習データ(titanic_training)のsex、embarkation_point列をOne-hot表現に変換するモデルを作成します。
|
1 2 3 4 5 6 |
dbadmin=> SELECT ONE_HOT_ENCODER_FIT('titanic_encoder', 'titanic_training', 'sex, embarkation_point'); ONE_HOT_ENCODER_FIT --------------------- Success (1 row) |
サマリー情報を確認します。 sex列は2種類、embarkation_pointは空白(NULL値)を除いて3種類のデータがあることがわかります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
dbadmin=> SELECT GET_MODEL_SUMMARY(USING PARAMETERS model_name='titanic_encoder'); GET_MODEL_SUMMARY ---------------------------------------------------------------------------------- =========== call_string =========== SELECT one_hot_encoder_fit('public.titanic_encoder','titanic_training','sex, embarkation_point' USING PARAMETERS exclude_columns='', output_view='', extra_levels='{}'); ================== varchar_categories ================== category_name |category_level|category_level_index -----------------+--------------+-------------------- embarkation_point| C | 0 embarkation_point| Q | 1 embarkation_point| S | 2 embarkation_point| | 3 sex | female | 0 sex | male | 1 (1 row) |
学習データ(titanic_training)、テストデータ(titanic_testing)に対して、先ほど作成したtitanic_encoderモデルを使用してOne-hot表現に変換するビューを作成します。
●学習データ(titanic_training)のOne-hot表現変換
|
1 2 3 4 5 |
dbadmin=> CREATE VIEW titanic_training_encoded AS SELECT passenger_id, survived, pclass, sex_1, age, -> sibling_and_spouse_count, parent_and_child_count, fare, embarkation_point_1, embarkation_point_2 -> FROM (SELECT APPLY_ONE_HOT_ENCODER(* USING PARAMETERS model_name='titanic_encoder') -> FROM titanic_training) AS sq; CREATE VIEW |
●テストデータ(titanic_training)のOne-hot表現変換
|
1 2 3 4 5 |
dbadmin=> CREATE VIEW titanic_testing_encoded AS SELECT passenger_id, name, pclass, sex_1, age, -> sibling_and_spouse_count, parent_and_child_count, fare, embarkation_point_1, embarkation_point_2 -> FROM (SELECT APPLY_ONE_HOT_ENCODER(* USING PARAMETERS model_name='titanic_encoder') -> FROM titanic_testing) AS sq; CREATE VIEW |
学習データ(titanic_training_encoded)、テストデータ(titanic_testing_encoded)を確認すると、sex、embarkation_point列がOne-hot表現に変換されていることが確認できます。
●学習データ(titanic_training_encoded)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
dbadmin=> SELECT * FROM titanic_training_encoded LIMIT 10; passenger_id | survived | pclass | sex_1 | age | sibling_and_spouse_count | parent_and_child_count | fare | embarkation_point_1 | embarkation_point_2 --------------+----------+--------+-------+-----+--------------------------+------------------------+---------+---------------------+--------------------- 1 | 0 | 3 | 1 | 22 | 1 | 0 | 7.25 | 0 | 1 2 | 1 | 1 | 0 | 38 | 1 | 0 | 71.2833 | 0 | 0 3 | 1 | 3 | 0 | 26 | 0 | 0 | 7.925 | 0 | 1 4 | 1 | 1 | 0 | 35 | 1 | 0 | 53.1 | 0 | 1 5 | 0 | 3 | 1 | 35 | 0 | 0 | 8.05 | 0 | 1 6 | 0 | 3 | 1 | | 0 | 0 | 8.4583 | 1 | 0 7 | 0 | 1 | 1 | 54 | 0 | 0 | 51.8625 | 0 | 1 8 | 0 | 3 | 1 | 2 | 3 | 1 | 21.075 | 0 | 1 9 | 1 | 3 | 0 | 27 | 0 | 2 | 11.1333 | 0 | 1 10 | 1 | 2 | 0 | 14 | 1 | 0 | 30.0708 | 0 | 0 (10 rows) |
●テストデータ(titanic_testing_encoded)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
dbadmin=> SELECT * FROM titanic_testing_encoded LIMIT 10; passenger_id | name | pclass | sex_1 | age | sibling_and_spouse_count | parent_and_child_count | fare | embarkation_point_1 | embarkation_point_2 --------------+----------------------------------------------+--------+-------+-----+--------------------------+------------------------+---------+---------------------+--------------------- 893 | Wilkes, Mrs. James (Ellen Needs) | 3 | 0 | 47 | 1 | 0 | 7 | 0 | 1 894 | Myles, Mr. Thomas Francis | 2 | 1 | 62 | 0 | 0 | 9.6875 | 1 | 0 895 | Wirz, Mr. Albert | 3 | 1 | 27 | 0 | 0 | 8.6625 | 0 | 1 896 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | 3 | 0 | 22 | 1 | 1 | 12.2875 | 0 | 1 897 | Svensson, Mr. Johan Cervin | 3 | 1 | 14 | 0 | 0 | 9.225 | 0 | 1 898 | Connolly, Miss. Kate | 3 | 0 | 30 | 0 | 0 | 7.6292 | 1 | 0 899 | Caldwell, Mr. Albert Francis | 2 | 1 | 26 | 1 | 1 | 29 | 0 | 1 900 | Abrahim, Mrs. Joseph (Sophie Halaut Easu) | 3 | 0 | 18 | 0 | 0 | 7.2292 | 0 | 0 901 | Davies, Mr. John Samuel | 3 | 1 | 21 | 2 | 0 | 24.15 | 0 | 1 902 | Ilieff, Mr. Ylio | 3 | 1 | | 0 | 0 | 7.8958 | 0 | 1 (10 rows) |
上記の場合、以下のようにマッピングされていることがわかります。
●sex列
Female→[0]、Male→[1]
●embarkation_point列
C→[0,0]、S→[0,1]、Q→[1,0]
モデル作成
One-hot表現に変換した後のデータ(titanic_training_encodedビュー)を学習データとして、survived(助かったか否か)を予測するロジスティック回帰モデルを作成します。|
1 2 3 4 5 6 7 |
dbadmin=> SELECT LOGISTIC_REG('titanic_log_reg', 'titanic_training_encoded', 'survived', '*' dbadmin(> USING PARAMETERS exclude_columns='passenger_id, survived'); LOGISTIC_REG --------------------------- Finished in 5 iterations (1 row) |
実装
※本例では評価ステップは割愛しています。作成したtitanic_log_regモデルを使用して、One-hot表現に変換したテストデータ(titanic_testing_encodedビュー)に対して、予測を行うことができました。
※予測結果はPREDICT_LOGISTIC_REG列の値を参照(0:死亡、1:生存)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
dbadmin=> SELECT passenger_id, name, -> PREDICT_LOGISTIC_REG(pclass, sex_1, age, sibling_and_spouse_count,parent_and_child_count, -> fare, embarkation_point_1, embarkation_point_2 -> USING PARAMETERS model_name='titanic_log_reg') -> FROM titanic_testing_encoded ORDER BY passenger_id LIMIT 10; passenger_id | name | PREDICT_LOGISTIC_REG --------------+----------------------------------------------+---------------------- 893 | Wilkes, Mrs. James (Ellen Needs) | 0 894 | Myles, Mr. Thomas Francis | 0 895 | Wirz, Mr. Albert | 0 896 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | 1 897 | Svensson, Mr. Johan Cervin | 0 898 | Connolly, Miss. Kate | 1 899 | Caldwell, Mr. Albert Francis | 0 900 | Abrahim, Mrs. Joseph (Sophie Halaut Easu) | 1 901 | Davies, Mr. John Samuel | 0 902 | Ilieff, Mr. Ylio | (10 rows) |
参考情報
Encoding Categorical Columnshttps://my.vertica.com/docs/9.0.x/HTML/index.htm#Authoring/AnalyzingData/MachineLearning/DataPreparation/EncodingCategoricalColumns.htm

