
Verticaでは、機械学習の分類アルゴリズムとしてランダムフォレストを利用できます。
目次
ランダムフォレストとは
ランダムフォレストは、機械学習における教師あり学習で、分類を行う際に利用できます。ランダムフォレストの利用例は以下の通りです。
・クレジットカードの不正利用検出
・テキストの分類
以降では、サンプルデータを例にVerticaでランダムフォレストを利用する手順をご紹介します。
Verticaでランダムフォレストを利用する手順
サンプルスキーマ、データのダウンロード
以下URLよりサンプルファイルをダウンロードします。https://github.com/vertica/Machine-Learning-Examples
画面右上にある「Clone or Download」をクリックします。
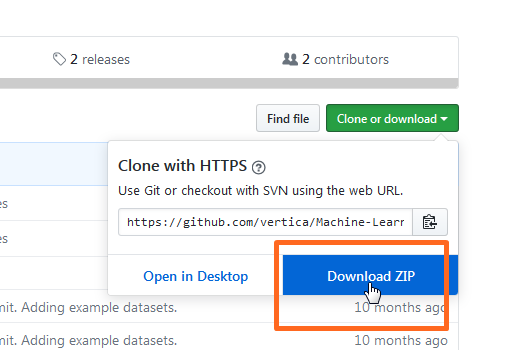
展開される画面の右下にある「Download ZIP」をクリックしてファイルを保存します。
サンプルスキーマの作成、データのロード
ダウンロードしたファイルをVerticaサーバ上の任意のディレクトリに転送します。転送後、以下コマンドでファイルを解凍します。
|
1 2 |
$ cd $ unzip Machine-Learning-Examples-master.zip |
解凍後に以下コマンドでサンプルスキーマとテーブルの作成、データロードを実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
$ cd Machine-Learning-Examples-master/data $ /opt/vertica/bin/vsql -d <データベース名> -w <パスワード> -f load_ml_data.sql DROP TABLE DROP TABLE DROP TABLE CREATE TABLE ~途中、省略~ COMMIT CREATE TABLE CREATE TABLE 以下のようなテーブルが作成されます。 dbadmin=> \d List of tables Schema | Name | Kind | Owner | Comment --------+-------------------+-------+---------+--------- public | agar_dish | table | dbadmin | public | agar_dish_1 | table | dbadmin | public | agar_dish_2 | table | dbadmin | public | baseball | table | dbadmin | public | dem_votes | table | dbadmin | public | faithful | table | dbadmin | public | faithful_testing | table | dbadmin | public | faithful_training | table | dbadmin | public | house84 | table | dbadmin | public | house84_clean | table | dbadmin | public | house84_test | table | dbadmin | public | house84_train | table | dbadmin | public | iris | table | dbadmin | public | iris1 | table | dbadmin | public | iris2 | table | dbadmin | public | mtcars | table | dbadmin | public | mtcars_test | table | dbadmin | public | mtcars_train | table | dbadmin | public | rep_votes | table | dbadmin | public | salary_data | table | dbadmin | public | transaction_data | table | dbadmin | (21 rows) |
ランダムフォレストモデルの作成
本記事では機械学習のサンプルデータとしてよく用いられるirisデータを使用します。irisデータには「あやめ」の3品種「setosa」、「versicolor」、「virginica」のSepal(がく片)の長さと幅、及びPetal(花びら)の長さと幅の情報が含まれています。
|
1 2 3 4 5 6 7 |
dbadmin=> SELECT * FROM iris WHERE id=1 OR id=51 OR id=101; id | Sepal_Length | Sepal_Width | Petal_Length | Petal_Width | Species -----+--------------+-------------+--------------+-------------+------------ 1 | 5.1 | 3.5 | 1.4 | 0.2 | setosa 51 | 7 | 3.2 | 4.7 | 1.4 | versicolor 101 | 6.3 | 3.3 | 6 | 2.5 | virginica (3 rows) |
 アヤメのイメージ写真
アヤメのイメージ写真
Sepal(がく片)の長さと幅、及びPetal(花びら)の長さと幅の情報を用いて機械学習を行い、学習データから花の品種を予測する分類を行います。
サンプルデータセットでは、すでにirisデータを分割した学習データ(iris1)とテストデータ(iris2)が用意されています。そのため、iris1テーブルを用いてランダムフォレストによる機械学習を行います。
ランダムフォレストによる機械学習を行うには、RF_CLASSIFIER関数を利用します。
|
1 2 3 4 5 6 |
dbadmin=> SELECT RF_CLASSIFIER ('myRFModel', 'iris1', 'Species', 'Sepal_Length, Sepal_Width, Petal_Length, Petal_Width' USING PARAMETERS ntree=100, sampling_size=0.5); RF_CLASSIFIER ------------------- Finished training (1 row) |
【参考】パラメータの意味
| パラメータ名 | 意味 |
|---|---|
| myRFModel | 任意のモデル名 |
| iris1 | 学習データのテーブル名 |
| Species | 予測したい列(目的変数) |
| Sepal_Length, Sepal_Width, Petal_Length, Petal_Width | 予測に使用する説明変数 |
| ntree | (オプション)フォレスト内のツリーの数 |
| sampling_size | (オプション)各ツリーをトレーニングするために入力データセットのどの程度ランダムに選択するかを指定する数値 |
サマリを出力
作成したmyRFModelモデルのサマリ情報を確認します。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
dbadmin=> dbadmin=> SELECT GET_MODEL_SUMMARY(USING PARAMETERS model_name='myRFModel'); GET_MODEL_SUMMARY ------------------------------------------------------ =========== call_string =========== SELECT rf_classifier('public.myRFModel', 'iris1', '"species"', 'Sepal_Length, Sepal_Width, Petal_Length, Petal_Width' USING PARAMETERS exclude_columns='', ntree=100, mtry=2, sampling_size=0.5, max_depth=5, max_breadth=32, min_leaf_size=1, min_info_gain=0, nbins=32); ======= details ======= predictor |type ------------+----- sepal_length|float sepal_width |float petal_length|float petal_width |float =============== Additional Info =============== Name |Value ------------------+----- tree_count | 100 rejected_row_count| 0 accepted_row_count| 90 (1 row) |
作成したモデルの評価
学習時に利用していないテストデータ(iris2)を利用して、作成したモデルの精度を評価します。ランダムフォレストによる予測を行う場合はPREDICT_RF_CLASSIFIER関数を使用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
dbadmin=> SELECT id, species ,PREDICT_RF_CLASSIFIER (Sepal_Length, Sepal_Width, Petal_Length, Petal_Width USING PARAMETERS model_name='myRFModel') FROM iris2; id | species | PREDICT_RF_CLASSIFIER -----+------------+----------------------- 5 | setosa | setosa 10 | setosa | setosa 14 | setosa | setosa 15 | setosa | setosa 21 | setosa | setosa 22 | setosa | setosa 24 | setosa | setosa 25 | setosa | versicolor ★ 32 | setosa | setosa 33 | setosa | setosa 34 | setosa | setosa 35 | setosa | setosa 38 | setosa | setosa 39 | setosa | setosa 42 | setosa | setosa 43 | setosa | setosa 45 | setosa | versicolor ★ 46 | setosa | setosa 47 | setosa | setosa 48 | setosa | setosa 51 | versicolor | versicolor 54 | versicolor | versicolor 57 | versicolor | versicolor 59 | versicolor | versicolor 62 | versicolor | versicolor 63 | versicolor | versicolor 64 | versicolor | versicolor 65 | versicolor | versicolor 66 | versicolor | versicolor 71 | versicolor | virginica ★ 73 | versicolor | versicolor 75 | versicolor | versicolor 82 | versicolor | versicolor 87 | versicolor | versicolor 89 | versicolor | versicolor 90 | versicolor | versicolor 91 | versicolor | versicolor 96 | versicolor | versicolor 97 | versicolor | versicolor 101 | virginica | virginica 102 | virginica | virginica 104 | virginica | virginica 107 | virginica | virginica 110 | virginica | virginica 113 | virginica | virginica 115 | virginica | virginica 118 | virginica | virginica 119 | virginica | virginica 120 | virginica | versicolor ★ 127 | virginica | virginica 129 | virginica | virginica 133 | virginica | virginica 134 | virginica | versicolor ★ 136 | virginica | virginica 141 | virginica | virginica 142 | virginica | virginica 143 | virginica | virginica 145 | virginica | virginica 146 | virginica | virginica 148 | virginica | virginica (60 rows) |
★のデータについては、間違った分類を行っていますが、それ以外は期待した分類が行われていることが確認できます。
また、PREDICT_RF_CLASSIFIER_CLASSES関数を利用することで、分類される条件に合致する確率も併せて求めることができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
dbadmin=> SELECT id, species, PREDICT_RF_CLASSIFIER_CLASSES(Sepal_Length, Sepal_Width, Petal_Length, Petal_Width USING PARAMETERS model_name='myRFModel') OVER (partition by id,species) FROM iris2 ORDER BY 4; id | species | predicted | probability -----+------------+------------+------------------- 107 | virginica | virginica | 0.536992818870368 134 | virginica | versicolor | 0.56202162322828 45 | setosa | versicolor | 0.577060814173363 25 | setosa | versicolor | 0.577060814173363 120 | virginica | versicolor | 0.637935043141699 127 | virginica | virginica | 0.672532824186689 71 | versicolor | virginica | 0.675916450364433 73 | versicolor | versicolor | 0.824883846576117 51 | versicolor | versicolor | 0.833527853168653 104 | virginica | virginica | 0.844583524605197 66 | versicolor | versicolor | 0.88494397517301 87 | versicolor | versicolor | 0.88494397517301 57 | versicolor | versicolor | 0.905777308506343 115 | virginica | virginica | 0.917643097643098 143 | virginica | virginica | 0.917643097643098 102 | virginica | virginica | 0.917643097643098 62 | versicolor | versicolor | 0.917696797514068 75 | versicolor | versicolor | 0.918307070411105 59 | versicolor | versicolor | 0.918307070411105 63 | versicolor | versicolor | 0.923321797514068 89 | versicolor | versicolor | 0.923373489243391 142 | virginica | virginica | 0.925976430976431 148 | virginica | virginica | 0.925976430976431 146 | virginica | virginica | 0.925976430976431 96 | versicolor | versicolor | 0.926230632100534 64 | versicolor | versicolor | 0.936741710933981 65 | versicolor | versicolor | 0.949236584481486 97 | versicolor | versicolor | 0.952093727338629 91 | versicolor | versicolor | 0.952569917814819 90 | versicolor | versicolor | 0.962569917814819 82 | versicolor | versicolor | 0.962569917814819 54 | versicolor | versicolor | 0.962569917814819 15 | setosa | setosa | 0.964624060150376 42 | setosa | setosa | 0.971111111111111 133 | virginica | virginica | 0.988703703703704 129 | virginica | virginica | 0.988703703703704 14 | setosa | setosa | 0.991111111111111 35 | setosa | setosa | 0.991111111111111 39 | setosa | setosa | 0.991111111111111 10 | setosa | setosa | 0.991111111111111 46 | setosa | setosa | 0.991111111111111 145 | virginica | virginica | 0.992037037037037 141 | virginica | virginica | 0.992037037037037 101 | virginica | virginica | 0.992037037037037 113 | virginica | virginica | 0.992037037037037 119 | virginica | virginica | 0.996666666666667 38 | setosa | setosa | 1 34 | setosa | setosa | 1 22 | setosa | setosa | 1 110 | virginica | virginica | 1 136 | virginica | virginica | 1 5 | setosa | setosa | 1 47 | setosa | setosa | 1 24 | setosa | setosa | 1 21 | setosa | setosa | 1 32 | setosa | setosa | 1 48 | setosa | setosa | 1 33 | setosa | setosa | 1 43 | setosa | setosa | 1 118 | virginica | virginica | 1 (60 rows) |
【参考】PREDICT_RF_CLASSIFIER、PREDICT_RF_CLASSIFIER_CLASSES関数のパラメータの意味
| パラメータ名 | 意味 |
|---|---|
| sepal_length,sepal_width,petal_length,petal_width | 予測に使用する列(モデル作成時に指定した説明変数) |
| MODEL_NAME | 予測に使用するモデル名 |
実装
作成したランダムフォレストモデルを実装する場合も、評価時に利用したPREDICT_RF_CLASSIFIER関数を利用できます。|
1 2 3 4 5 |
SELECT id, species , PREDICT_RF_CLASSIFIER (Sepal_Length, Sepal_Width, Petal_Length, Petal_Width USING PARAMETERS model_name='myRFModel') FROM <予測したいデータがあるテーブル>; |
参考情報
Random Forest for Classificationhttps://my.vertica.com/docs/9.0.x/HTML/index.htm#Authoring/AnalyzingData/MachineLearning/RandomForest/RandomForest.htm
検証バージョンについて
この記事の内容はVertica 9.0で確認しています。- 投稿タグ
- 機械学習, Machine Learning, iris, randam forest, ランダムフォレスト

