
目次
はじめに
Vertica Management Console(以下、MC)ではVerticaやサーバの稼働状況を様々な監視項目から一元管理することができます。システムの安定運用にあたっては、システムの監視要件に合わせて監視間隔を短くしたり、あるいは閾値を厳しくしたりするようなケースがあるかと思います。この記事では、Management Consoleで監視する項目の閾値の設定画面の説明と、実際に閾値を変更した時の動作確認の例をご紹介します。設定変更画面に移動する
MCにログインしたら、対象データベースを選択します。
まずは設定変更をするために閾値を管理するページに移動します。Overviewの画面下段にあるメニューから「Settings」を選択します。
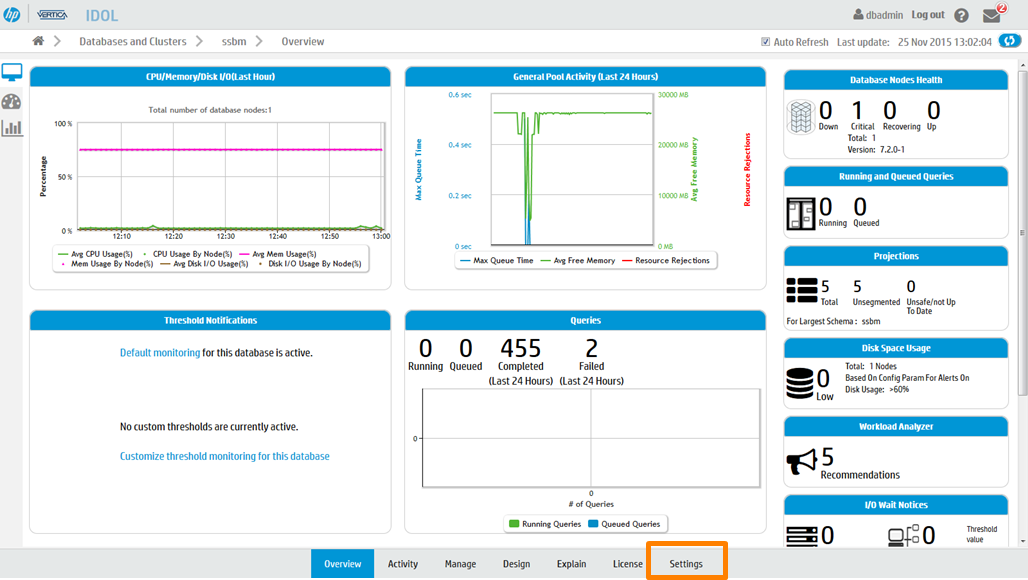
MCの設定画面に移動すると、左側に更に詳細設定のメニューが表示されます。一番下にある「Threshold」を選択します。
監視項目の設定画面に移動しました。
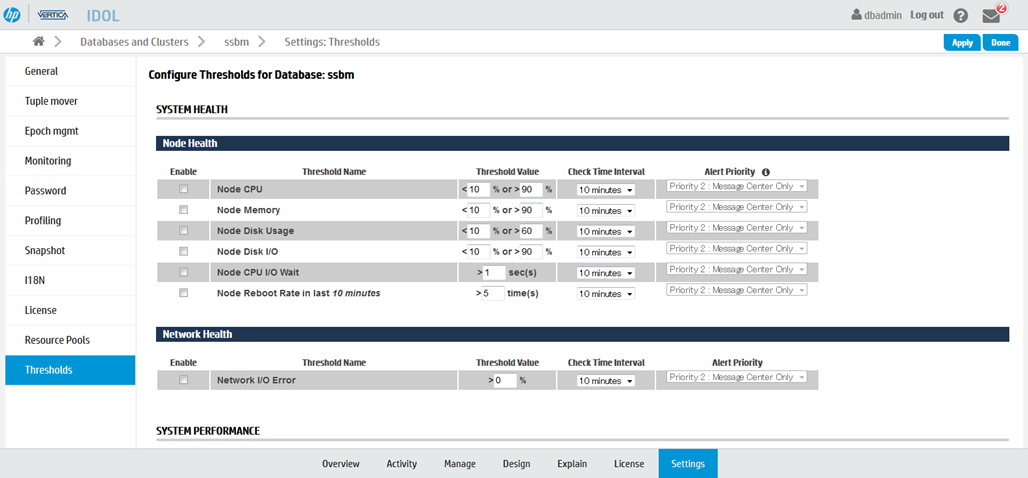
この画面では、以下の項目の閾値を設定することができます。
SYSTEM HEALTH
-Node Health ・・・クラスタを構成するノードのCPUやメモリ、IOに関する稼動状態の閾値
-Network Health・・・ネットワークのIOエラーの閾値
SYSTEM PERFORMANCE
-Query・・・・・・実行されたクエリに関する稼働状況の閾値
-Resource Pool・・リソースプールの制限や稼働状況の閾値
-Node Health ・・・クラスタを構成するノードのCPUやメモリ、IOに関する稼動状態の閾値
-Network Health・・・ネットワークのIOエラーの閾値
SYSTEM PERFORMANCE
-Query・・・・・・実行されたクエリに関する稼働状況の閾値
-Resource Pool・・リソースプールの制限や稼働状況の閾値
SYSTEM HEALTH
Node Health
クラスタを構成するノードのCPUやメモリ、IOに関する稼動状態の閾値
Network Health
ネットワークのIOエラーの閾値
SYSTEM PERFORMANCE
Query
実行されたクエリに関する稼働状況の閾値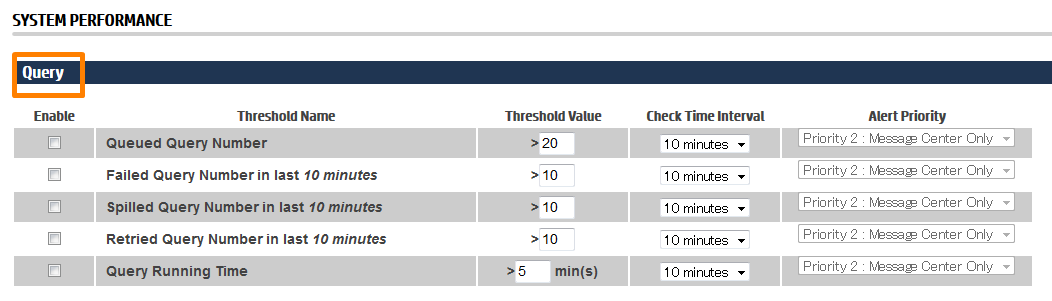
Resource Pool
リソースプールの制限や稼働状況の閾値
閾値を変更してみる ~DISK使用率~
それでは実際に閾値を変更してメッセージングのレベルが変わるか見てみましょう。ここでは、90%以上のDISK使用率になるとMessage Centerに通知が届くデフォルトの設定を「10%以上」と意図的に閾値を低く設定し、検知させやすい状態にしてみます。
閾値を90%から10%に変更
デフォルト「90%」を「10%」に変更します。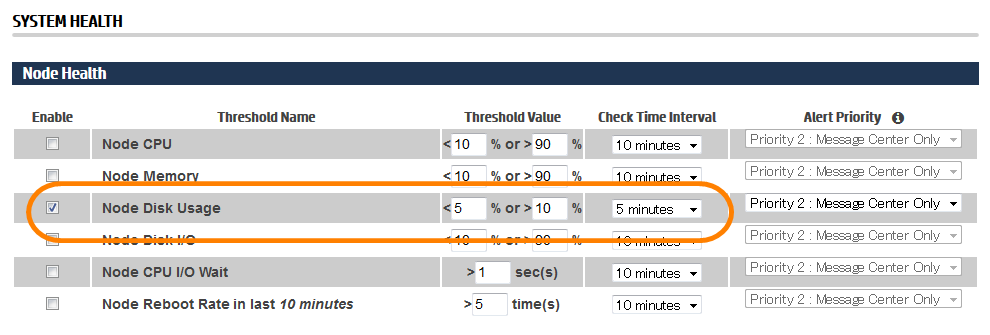
右上にある「Apply」ボタンをクリックして変更を反映させます。
この画面が表示されたら変更内容が反映されます。
DISK使用率を確認する
OSレベルでDISK使用率を確認します。今回の検証環境では、「/home/dbadmin」配下にデータベースを配置しました。
現在の使用状況は約29%です。
|
1 2 3 4 5 6 7 8 |
$ df -h Filesystem Size Used Avail Use% マウント位置 /dev/mapper/vg_keisrv1-lv_root 50G 40G 7.4G 85% / tmpfs 16G 15M 16G 1% /dev/shm /dev/sda1 485M 38M 423M 9% /boot /dev/mapper/vg_keisrv1-lv_home 181G 50G 123G 29% /home ★データベース配置先 |
今回の閾値である10%を超える使用率であるため、通知が上がってくることを確認します。

閾値を変更してみる ~CPU使用率~
次に、CPU使用率の閾値を変更してメッセージングのレベルが変わるか見てみたいと思います。デフォルトでは90%以上の閾値となっていますが、ここでは「5%以上」と極端に閾値を厳しくしてみます。
閾値を90%から5%に変更
デフォルト「90%」を「5%」に変更します。
右上にある「Apply」ボタンをクリックして変更を反映させます。
CPU使用率を確認する
OSレベルでCPU使用率を確認してみます。topコマンドでCPU使用率を見てみると、現在の使用状況は約1%です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Tasks: 144 total, 1 running, 143 sleeping, 0 stopped, 0 zombie Cpu(s): 2.7%us, 1.0%sy, 0.0%ni, 96.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 32883880k total, 6916444k used, 25967436k free, 406404k buffers Swap: 16515064k total, 0k used, 16515064k free, 2783112k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 22130 dbadmin 20 0 5169m 2.2g 30m S 1.0 7.0 39:49.01 vertica ★CPU使用率は1%未満 2314 dbadmin 20 0 836m 45m 6920 S 0.7 0.1 99:01.57 python 2317 dbadmin 20 0 3117m 642m 15m S 0.7 2.0 62:00.64 java 24532 dbadmin 20 0 15032 1260 956 R 0.7 0.0 0:00.02 top 1415 root 20 0 0 0 0 S 0.3 0.0 1:55.06 flush-253:2 22128 dbadmin 20 0 18812 3132 1068 S 0.3 0.0 0:01.97 spread 1 root 20 0 19348 1552 1224 S 0.0 0.0 0:08.47 init 2 root 20 0 0 0 0 S 0.0 0.0 0:00.06 kthreadd ~以降省略~ |
ここで負荷の高い処理を実行してみます。処理実行途中にtopコマンドで見てみたところverticaプロセスのCPU使用率は約89%でした。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Tasks: 144 total, 1 running, 143 sleeping, 0 stopped, 0 zombie Cpu(s): 2.3%us, 5.7%sy, 92.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 32883880k total, 8937732k used, 23946148k free, 406464k buffers Swap: 16515064k total, 0k used, 16515064k free, 2785308k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 22130 dbadmin 20 0 5542m 2.5g 30m S 89.1 7.8 46:48.84 vertica ★CPU使用率は89% 27202 dbadmin 20 0 129m 2932 2052 S 9.2 0.0 4:32.60 vsql 2314 dbadmin 20 0 836m 45m 6920 S 0.7 0.1 99:07.44 python 1362 root 20 0 175m 4380 3576 S 0.3 0.0 5:51.71 vmtoolsd 2317 dbadmin 20 0 3117m 644m 15m S 0.3 2.0 62:10.59 java 28847 dbadmin 20 0 15032 1260 956 R 0.3 0.0 0:00.04 top 1 root 20 0 19348 1552 1224 S 0.0 0.0 0:08.47 init |
今回5分間隔での監視設定としていたので、設定後に以下のような通知が上がってくること確認できました。

まとめ
このように、MCの監視閾値を任意の数値に変更することで、システム要件に合わせてVerticaの運用監視を効率良く行うことができます。今回ご紹介した項目以外にも調整可能な監視項目がありますので、適宜調整の上ご利用ください。

