
はじめに
IMPUTE関数を利用するとデータの欠損値を平均値/最頻値で補完することができます。例えば、機械学習のためのデータを準備する際に欠損値がある行を削除するのではなく、IMPUTE関数を利用して補完することで、より多くのデータを学習データとして利用できます。
IMPUTE
コマンド構文
|
1 2 3 |
dbadmin=>SELECT IMPUTE( 'output‑view', 'input‑relation', 'input‑columns', 'method' [ USING PARAMETERS [exclude_columns='excluded‑columns'] [, partition_columns='partition‑columns'] ] ) |
| パラメータ名 | 内容 |
|---|---|
| output‑view | 欠損値補完後の結果を格納するビュー |
| input‑relation | 欠損値補完対象のテーブル、ビュー |
| input‑columns | 欠損値補完対象の列。複数列指定する場合は「,」カンマで区切ります。 |
| method | mean:平均値を補完します。このパラメータは数値データに対してのみ利用できます。 mode:最頻値を補完します。このデータはカテゴリカルデータ(文字データ)に対してのみ利用できます。 |
| exclude_columns | (オプション) input‑columns*で(全列)と指定した場合に、対象列から除外する列 |
| partition_columns | (オプション) パーティションを定義する場合のパーティション列。複数列指定する場合は「,」カンマで区切ります。 |
利用例
例として車のデータであるmtcarsテーブルの欠損値を補完します。1) mtcarsテーブルには30件のデータが格納されています。データを確認すると15、30行目のwt(重量)列に欠損があることが確認できます。
※クリックで画像拡大

2) 欠損値に対して、IMPUTE関数を使用してwt列の平均値で補完します。
|
1 2 3 4 5 6 |
dbadmin=> SELECT IMPUTE('impute_mtcars', 'mtcars', 'wt', 'mean'); IMPUTE -------------------------- Finished in 1 iteration (1 row) |
3) 作成されたimpute_mtcarsビューを確認すると、欠損値が補完されていることが確認できます。
※クリックで画像拡大
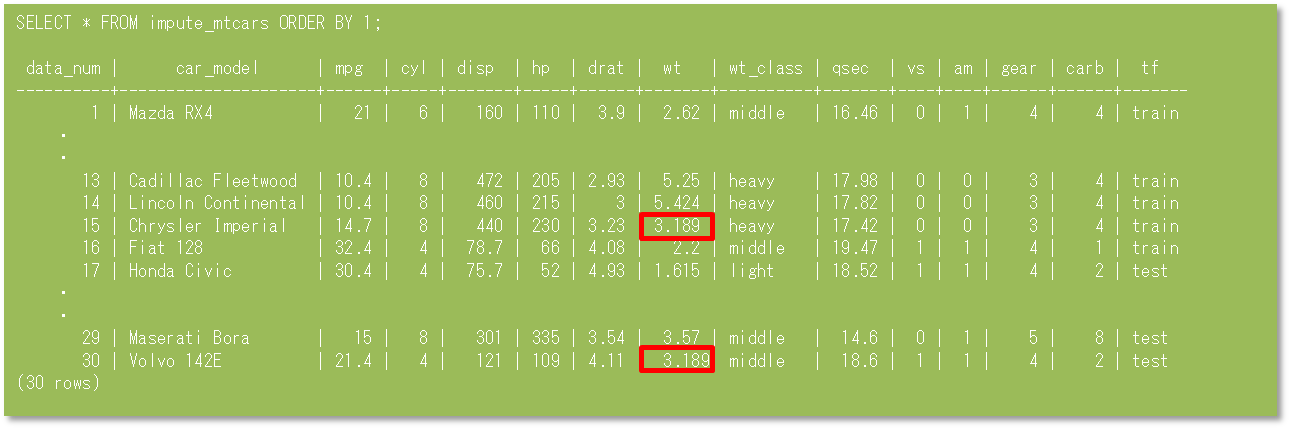
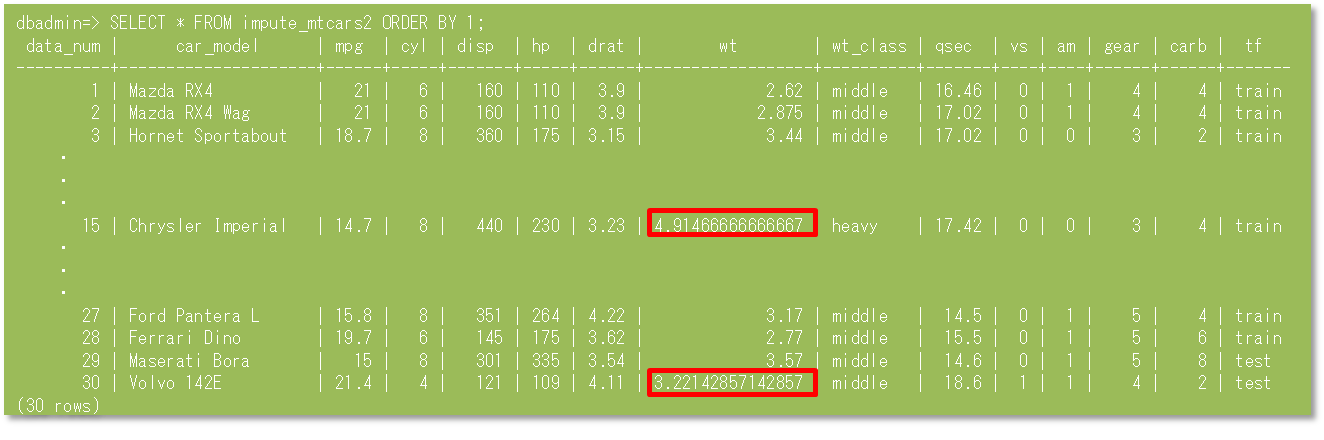
4)上記手順では全行の平均値を一律補完していますが、PARTITION_COLUMNSオプションを利用すると、よりきめ細やかな補完ができます。そこで、本例ではPARTITION_COLUMNSオプションを利用してwt_class列単位の平均値を補完するimpute_mtcars2ビューを作成します。
|
1 2 3 4 5 6 |
dbadmin=> SELECT IMPUTE('impute_mtcars2', 'mtcars', 'wt', 'mean' USING PARAMETERS PARTITION_COLUMNS='wt_class'); IMPUTE -------------------------- Finished in 1 iteration (1 row) |
5) 15行目はwt_class=heavyの値の平均値、30行目はwt_class=middleの値の平均値でそれぞれ補完されました。
※クリックで画像拡大
参考情報
Sampling Datahttps://my.vertica.com/docs/9.1.x/HTML/index.htm#Authoring/SQLReferenceManual/Functions/MachineLearning/IMPUTE.htm
検証バージョンについて
この記事の内容はVertica 9.1で確認しています。- 投稿タグ
- データ準備, 欠損値, 機械学習, Machine Learning

