
はじめに
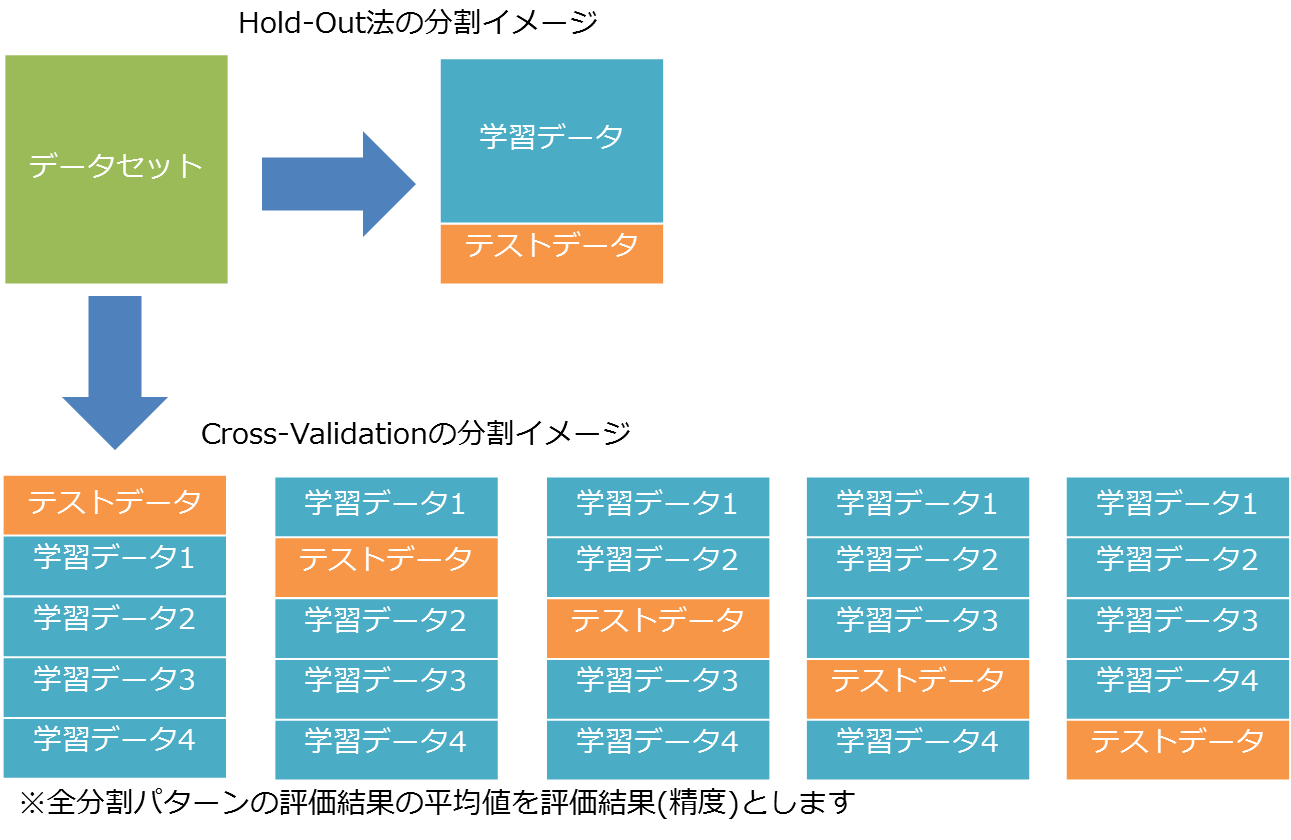
機械学習を行う際、最適なアルゴリズムやパラメータを見極めるための評価手法としてCross-Validation(交差検証)を使用することができます。例えば、10,000件のデータで予測モデルを作成する場合、学習データ7,000件、テストデータ3,000件といった分け方としたとします。(これをHold-Out法と言います)
Hold-Out法でランダムに分けたとしても学習データの内容に偏りがあったりすると過学習(Overfitting)等が発生し、モデルの性能に影響することがあります。
Cross-Validationを使用すると、例えば10,000件のデータを5分割し、その内4個を学習データ、1個をテストデータとして学習→評価を行い、さらにそれを分割数分(5回)実施してくれます。これにより、Hold-Out法と比較し、より正確な評価を行うことができます。
また、アルゴリズムを変えてCross-Validationを利用することで、アルゴリズムごとの精度を確認できるため、最適なアルゴリズムを見つけやすくなります。
さらに、ハイパーパラメータと試したい値を指定することで、パラメータ値ごとの評価を行ってくれます。これにより、最適なパラメータ値を見つけやすくなります。
Vertica 9.0より、CROSS_VALIDATE関数を使用することで、上記のようなCross-Validationによる評価が行えるようになりました。
※Vertica 9.0時点で実施できるCross-ValidationはK分割クロスバリデーションのみです。
CROSS_VALIDATE
コマンド構文
|
1 2 3 4 5 6 7 8 |
dbadmin=> SELECT CROSS_VALIDATE ( 'algorithm', 'input_relation', 'response_column', 'predictor_columns' -> [ USING PARAMETERS [exclude_columns='col1, col2, ... coln',] -> [cv_model_name='string',] -> [cv_metrics= 'value',] -> [cv_fold_count= value,] -> [cv_hyperparams= 'json_string',] -> [cv_prediction_cutoff=cutoff_value,] -> ]); |
| パラメータ名 | 意味 |
|---|---|
| algorithm | 検証するアルゴリズム ※V9.0時点で使用できるアルゴリズムはsvm_classifier(SVM分類), naive_bayes(ナイーブベイズ分類),logistic_reg(ロジスティック回帰)のみです。 |
| input_relation | 対象テーブル名 |
| response_column | 目的変数 |
| exclude_columns | (オプション) 予測列を*(全列)と指定した場合に、予測列から除外する列 |
| cv_model_name | (オプション) 評価結果を保存する場合の名前。本パラメータを使用しない場合、評価結果は表示されますが保存されません。 |
| cv_fold_count | (オプション) データの分割数(デフォルト:5) |
| cv_hyperparams | (オプション) 検証したいハイパーパラメータ名と値 |
| cv_prediction_cutoff | (オプション) ロジスティック回帰の予測段階に渡されるカットオフしきい値。(デフォルト:0.5) |
Vertica 9.2から、分類アルゴリズムだけでなく、LINEAR_REGとSVM_REGRESSORの回帰アルゴリズムでも利用できるようになりました。また、精度結果の評価手法として指定するメトリクスに、MSE、MAE、rsquared、explained_varianceを指定できるようになりました。
利用例(アルゴリズムの比較)
mtcarsテーブルのam列を予測するようなモデルを例に、Cross-Validationによるアルゴリズムごとの精度の比較を行います。●サポートベクターマシンを使用した場合
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
dbadmin=> SELECT CROSS_VALIDATE('svm_classifier', 'mtcars', 'am', 'cyl, mpg, wt, hp, gear' USING PARAMETERS -> cv_fold_count= 6, -> cv_metrics='accuracy,error_rate'); CROSS_VALIDATE ------------------------------------------------------------------------------------------------------------- Finished =========== run_average =========== accuracy|error_rate --------+---------- 0.86528| 0.13472 (1 row) |
●ロジスティック回帰を使用した場合
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
dbadmin=> SELECT CROSS_VALIDATE('logistic_reg', 'mtcars', 'am', 'cyl, mpg, wt, hp, gear' USING PARAMETERS -> cv_fold_count= 6, -> cv_metrics='accuracy,error_rate'); CROSS_VALIDATE ------------------------------------------------------------------------------------------------------------- Finished =========== run_average =========== accuracy|error_rate --------+---------- 0.91667| 0.08333 (1 row) |
上記のaccuracy(正解率)、error_rate(不正解率)を比較すると、ロジスティック回帰の方が良い精度であることが確認できます。
このように、どのアルゴリズムを使用するかの判断の方法としてCross-Validationが使用できます。
利用例(ハイパーパラメータの比較)
上記のサポートベクターマシンを例に、Cross-Validationによるハイパーパラメータ値毎の精度の比較を行います。本例ではサポートベクターマシンのハイパーパラメータの一つである「C」(コストパラメータ)をC=1、C=5にした場合で比較します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
dbadmin=> SELECT CROSS_VALIDATE('svm_classifier', 'mtcars', 'am', 'cyl, mpg, wt, hp, gear' USING PARAMETERS -> cv_fold_count= 6, cv_hyperparams='{"C":[1,5]}', -> cv_metrics='accuracy,error_rate'); CROSS_VALIDATE ----------------------------------------------------------------------------------------------------------------------------------------- Finished =========== run_average =========== C|accuracy|error_rate -+--------+---------- 1| 0.93889| 0.06111 5| 0.93889| 0.06111 (1 row) |
上記のaccuracy(正解率)、error_rate(不正解率)を比較すると、「C」の値は1、5どちらも同じ精度であることが確認できます。
参考情報
CROSS_VALIDATEhttps://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/SQLReferenceManual/Functions/MachineLearning/CROSS_VALIDATE.htm
検証バージョンについて
この記事の内容はVertica 9.0.1、9.2で確認しています。更新履歴
2019/07/09 Vertica 9.2の情報を追加2018/03/10 本記事を公開

