
目次
VerticaにおけるApache Kafka連携とは?
Verticaへのデータロードは、COPYコマンドを用いたCSVファイルのバルクロードで実施する方法が一般的です。INSERT文も使用できますが、Verticaのような列指向データベースは1件1件のINSERT処理よりも、ある程度まとまった件数をロードするバルクロードに向いています。そのため、これまでのバージョンでは、IoT端末が生成する大量のログデータやTwitterのつぶやきデータ等の逐次発生するデータをリアルタイムで取り込むことは難しいというのが現実でした。
(ETLツール等を用いて、少量のデータを逐次COPYコマンドでロードするような仕組みを作れば実現できますが、そういった仕組みはデータ同期等のことを考えると複雑になりがちです)
Vertica 7.2では、オープンソース分散型メッセージングシステムの「Apache Kafka」(以下Kafka)のネイティブサポートを提供することで、これらのデータをニア・リアルタイムで取り込むことが可能になりました。
Kafka連携機能を利用してTwitterのつぶやきデータを取り込む場合の構成例
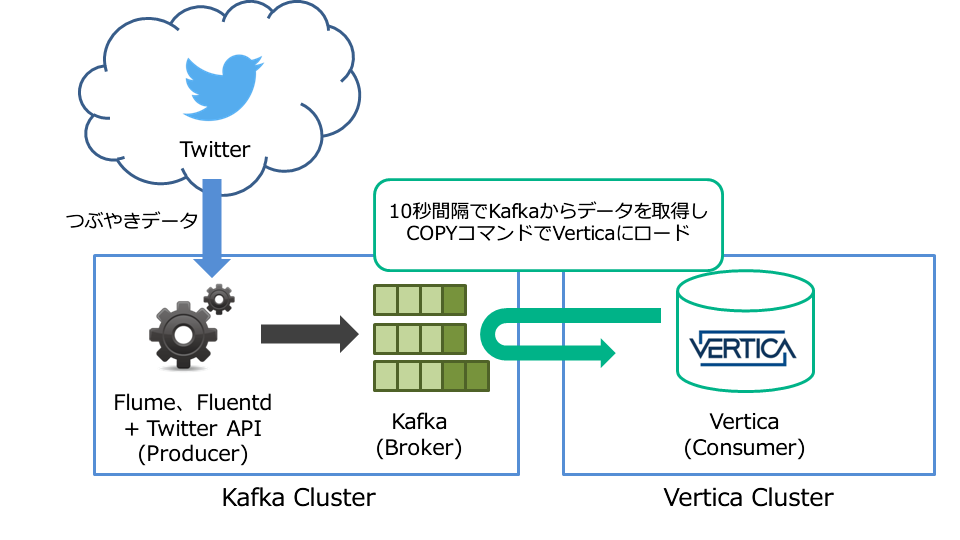
例えばTwitterのつぶやきデータを分析したい場合は、図のような構成で実現することができます。TwitterのつぶやきデータをApache Flumeやfluentdなどを使って収集し、Kafkaに送信します。Kafkaには送られてきたデータがキューとしてKafka Cluster内に次々と溜まっていきます。このキューに溜まっているデータの中から、分析に使用するデータをVerticaが一定間隔(図の場合は10秒間隔)で受け取りに行き、内部的にCOPYコマンドを使ってVerticaにロードします。
このように、INSERTではなくVerticaが得意とするCOPYコマンドを使用したバルクロードとして処理することで、ログデータ等の逐次発生するようなデータをVerticaにリアルタイムに取り込むことが可能です。ロードしたデータについては通常のテーブルに格納されるので、すぐに分析を行うことができます。
設定手順
以下にKafka連携機能を利用するための具体的な手順を記載します。0.事前準備
事前に任意のサーバにKafkaをインストールし、起動しておいてください。1.Kafka スケジューラの定義
vkconfig schedulerコマンドを使用して、接続先のKafkaサーバの情報や、Kafkaにデータを取得しに行く間隔等を指定します。設定例)
|
1 2 3 4 5 6 7 8 |
$ /opt/vertica/packages/kafka/bin/vkconfig scheduler --add \ --config-schema kafka_config \ --username dbadmin \ --password XXXXX \ --dbhost 172.16.XX.XX \ --dbport 5433 \ --frame-duration 00:00:10 \ --brokers localhost:9092 |
各パラメータの詳細は以下をご確認ください。
| 列名 | 内容 |
|---|---|
| add | 新しくスケジューラを定義する場合に使用します |
| config-schema | Kafka連携でスケジューラごとにVerticaが使用するスキーマを指定します。スキーマは自動で作成されるため事前に作成しておく必要はありません。 |
| username | Verticaに接続する際に使用するユーザ名を指定します |
| password | usernameに指定したユーザのログインパスワードを指定します |
| dbhost | 接続するVerticaのホスト名(IPアドレス)を指定します |
| dbport | 接続するVerticaのポート番号を指定します |
| frame-duration | VerticaがKafkaにデータを取得しにいく間隔(例の場合は10秒)を指定します |
| brokers | 接続するKafka brokerのホスト名、ポートを指定します |
2.データロード用のターゲットテーブルの作成
Kafkaから取得したデータをロードするためのテーブルを作成します。通常のCREATE TABLE文を使用してテーブルを作成することができます。
例)
|
1 |
dbadmin=> CREATE TABLE public.messages(col1 VARCHAR(300)); |
なお、ロードされるデータの内容が不明(半構造)な場合は、通常のテーブルではなく、Flex tableとして作成してください。
例)
|
1 |
dbadmin=> CREATE FLEX TABLE public.messages; |
3.Kafka Topicとターゲットテーブルの関連付け
KafkaではデータをTopicという単位で分類して格納しています。vkconfig topicコマンドを使用して取り込みたいKafkaのTopicとロード先のVerticaのテーブルとの関連付けを行います。設定例)
|
1 2 3 4 5 6 7 8 9 10 11 |
$ /opt/vertica/packages/kafka/bin/vkconfig topic --add \ --config-schema kafka_config \ --username dbadmin \ --password XXXX \ --dbhost 172.16.XX.XX \ --dbport 5433 \ --target public.messages \ --topic test \ --parser KafkaParser \ --rejection-table public.kafka_rej \ --start-offset START |
各パラメータの詳細は以下をご確認ください。
| 列名 | 内容 |
|---|---|
| add | 新しくtopicとターゲットテーブルを関連付ける場合に指定します |
| config-schema | 「1.Kafka スケジューラの定義」のconfig-schemaで指定したスキーマと同名のスキーマを指定します |
| username | Verticaに接続する際に使用するユーザ名を指定します |
| password | usernameに指定したユーザのログインパスワードを指定します |
| dbhost | 接続するVerticaのホスト名(IPアドレス)を指定します |
| dbport | 接続するVerticaのポート番号を指定します |
| target | Verticaのターゲットテーブル(データのロード先)を指定します |
| topic | データを取得するKafkaのTopicを指定します |
| rejection-table | ロードに失敗したデータの情報を格納するテーブルを指定します |
4.Kafkaスケジューラの実行
設定した内容でKafka連携を開始するためにvkconfig launchコマンドを実行します。本コマンドを実行すると、Kafka連携がスタートします。
設定例)
|
1 2 3 4 5 6 |
$ /opt/vertica/packages/kafka/bin/vkconfig launch \ --config-schema kafka_config \ --username dbadmin \ --password XXXX \ --dbhost 172.16.XX.XX \ --dbport 5433 |
各パラメータの詳細は以下をご確認ください。
| 列名 | 内容 |
|---|---|
| config-schema | 「1.Kafka スケジューラの定義」のconfig-schemaで指定したスキーマと同名のスキーマを指定します |
| username | Verticaに接続する際に使用するユーザ名を指定します |
| password | usernameに指定したユーザのログインパスワードを指定します |
| dbhost | 接続するVerticaのホスト名(IPアドレス)を指定します |
| dbport | 接続するVerticaのポート番号を指定します |
なお、定義の中にはパスワードが含まれているため、実際に運用する際は設定内容をプロパティファイルに記述し、ファイルを指定して実行する方法が推奨されます。
例えば、vkconfig launchの場合は以下のように記述します。
|
1 |
$ /opt/vertica/packages/kafka/bin/vkconfig launch --conf configFile.properties |
configFile.propertiesファイルの記述内容
|
1 2 3 4 5 6 |
#config.properties: config-schema kafka_config username dbadmin password test dbhost 172.16.XX.XX dbport 5433 |
また、今回使用していないその他のオプションについては、マニュアルの以下のページをご参考ください。
Kafka Utility Options
動作確認
今回はKafkaに付属している「kafka-console-producer.sh」を使用してKafkaにデータを送信した場合の動作を確認します。1.Kafkaへのデータ送信
「kafka-console-producer.sh」から以下のように「アシスト」「Vertica」「データベース」と、3つのメッセージを入力します。|
1 2 3 4 |
# sh bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test アシスト Vertica データベース |
2.Verticaのテーブルを検索
上記「2.データロード用のターゲットテーブルの作成」で作成したテーブルを検索すると、Kafkaに送信したデータがVerticaにロードされていることが確認できます。|
1 2 3 4 5 6 7 |
dbadmin=> SELECT * FROM messages ; col1 ------------ アシスト Vertica データベース (3 rows) |
なお、Kafka連携を終了する場合は以下のコマンドを実行します。
|
1 |
$ /opt/vertica/packages/kafka/bin/vkconfig shutdown |
検証バージョンについて
この記事の内容はVertica 7.2、Kafka 0.9で確認しています。- 投稿タグ
- Kafka

