
基幹系システムで慣れ親しんできた汎用データベースですが、大量データの検索/集計処理を主とする情報系システムで利用した場合、チューニングコストが大きくなるという課題があります。これらの課題を高性能なハードウェアと専用ソフトウェアの組み合わせで解決したのがDWHアプライアンスですが、導入コストによって採用を見送るケースも少なくありません。
近年、大規模なデータを高速かつ高い頻度で分析するニーズは広がりをみせており、それに応えるべく登場したのが、Verticaなどの検索機能特化型の列指向型データベースです。
列でデータを保持し、必要な列のみアクセス
汎用データベースが行単位で行うのに対して、列指向型データベースは列単位にデータの格納とアクセスを行います。以下の図の例では、注文表から注文日が2011年の行を対象に売上高(価格×数量)を集計する処理を行っています。注文日と価格、数量を取り出すだけで結果を導くことができるため、対象となる3つの列が格納されているデータ領域にのみアクセスすることで、行ベースでデータが格納されている場合と比較して、無駄なディスクI/Oを省き処理性能を向上させることができます。データベースにおける最大のボトルネックはディスクI/Oです。一般的に、処理時間の2/3~4/5はディスクI/Oとなっており、そのディスクI/Oを減らすことで性能向上を図るのが列指向型データベースのアプローチです。
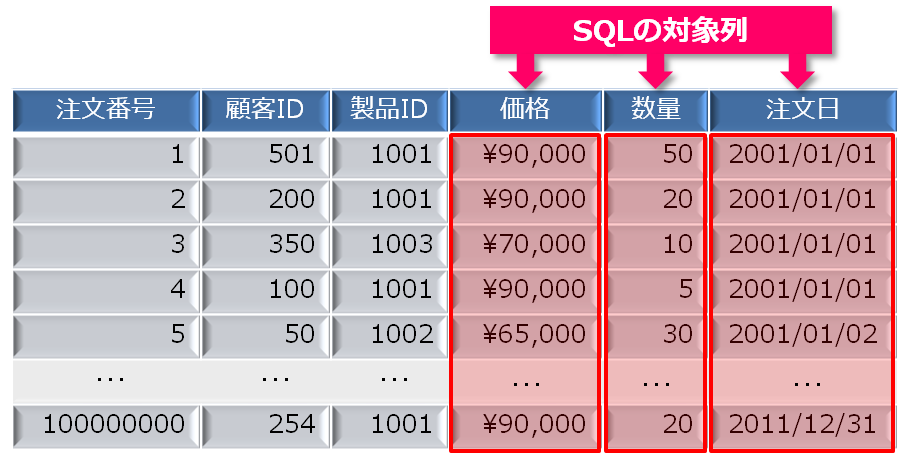
それでは、無駄なI/Oが、実際のところどの程度なのかを考えてみます。
ブロック内には、列データとは別に、ブロックヘッダと行ヘッダが含まれています。そのため、1ブロックに格納できる行数は、各種ヘッダ部分を除いた「ブロック・サイズ÷行サイズ」で計算できます。
例えば、
・ブロック・サイズ = 8KB
・行サイズ = 100バイト
・データ件数 = 1億件
・必要な列の合計サイズ = 20バイト
・行サイズ = 100バイト
・データ件数 = 1億件
・必要な列の合計サイズ = 20バイト
だとしたら、
・ブロックに格納される行数 = 80行(8KB÷100バイト)
・全件アクセス時のI/O数 = 125万ブロック(1億件÷80行)
・アクセスしたい列のI/O数 = 25万ブロック(125万ブロック×(20バイト÷100バイト))
・無駄なI/O数 = 100万ブロック(125万ブロック – 25万ブロック)
・全件アクセス時のI/O数 = 125万ブロック(1億件÷80行)
・アクセスしたい列のI/O数 = 25万ブロック(125万ブロック×(20バイト÷100バイト))
・無駄なI/O数 = 100万ブロック(125万ブロック – 25万ブロック)
ということになります。言い換えれば、
2GB(25万ブロック×8KB)のデータを分析するのに、10GB(125万ブロック×8KB)ものデータを読み込んで、その内8GB(100万ブロック×8KB)のデータを捨てている
ということです。
情報系システムではこのような処理がほとんどのため、汎用データベースを使うのはかなりもったいないといえます。列指向型データベースなら無駄な列にはアクセスしないため、それだけでも数倍は処理が速いのは誰でもわかりますね。
列方向で効率の良いデータ圧縮
列指向にはもう1つメリットがあります。それはデータ圧縮です。以下の図のように、列単位にデータを格納することで、同じ領域内に同一データが集まります。例えば、性別は2種類で、年齢や都道府県は数10種類ありますが、これらのデータは重複して存在します。このように重複データが多いとデータ圧縮の効果が非常に高く、データ領域をコンパクトに抑えることができます。さらに、領域サイズが小さいと、該当する列からのデータ抽出時のディスクI/Oも減らすことができるため、性能向上にも一役買っています。当然ですが、圧縮すると解凍も必要になります。解凍処理も列単位で行えるため、無駄な列データまで解凍することがなく、CPU負荷を抑えて効率的に行うことができます。
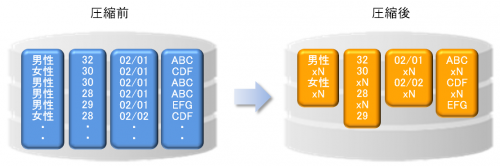
以上のように、列指向型データベースは行ベースの汎用データベースと比べ、情報系システムにおける優位性を持ちます。
Verticaは列指向の特性を持ちつつ、さらに進化した検索機能特化型データベースです。
参考情報
他の列指向型データベースにないVerticaの優位性については、こちらの記事でご紹介します。・Verticaとは
http://vertica-tech.ashisuto.co.jp/about-vertica/

